
The robots.txt file is important and the first thing you need to check when you are running a technical seo audit.
Even though it is a simple file but a single mistake can stop search engines to crawl and index your website.
In today’s post you will learn how to setup perfect robots txt file for your websites.
Let dive in:
What is Robots.txt file?
A robots.txt file is text file that instructs crawlers how to crawl pages on websites. It is a text file that webmasters put in root directory in their website.
All major search engines takes robots file seriously and follow its instruction.
Here is the basic format of robots.txt file.
User-agent: [user-agent name]
Disallow: [URL string not to be crawled]
Why Robots.txt is important?
Robots.txt file contains syntax that tells search engines to which page they need to crawl and which page ignore.
Here is how robots.txt file looks:
Blocking all web crawlers from contnet
User-agent: *
Disallow: /
The asterisk after User-agent: means all search engine allows to crawl the website.
The slash after “Disallow” tells search engines not to crawl any page on the website. People often make mistake and use this and later wonder why they are not ranking.
Allowing all web crawlers access to all content.
User-agent: *
Allow:
This is syntax tells all web crawlers to crawl all pages present on website.
Blocking a specific crawler to access to all content.
User-agent: Yahoo
Disallow: /blog
This syntax tells only Yahoo not to crawl any page on website that contains the URL string www.abc.com/blog
Do I Need Robots txt file?
Umm… not exactly.
Because Google is now smart enough to find all important pages on your website.
And, they will ignore pages which are not important or having a duplicate content.
Here are top three reasons why should you use robots txt file.
- Block non-public pages – You might have some pages on your website that you don’t want people access through search engine. These pages might be login page, payment page, etc.
These pages are important but it shouldn’t be accessible to all users.
- Increase crawl budget – It is important that all pages on your website indexed in search engine. But in some cases it doesn’t happens because of crawl budget issue.
By blocking low priority pages you can increase your crawl budget. In other words, Googlebot will spend more time on your website to find and crawl important pages.
- Stop indexing of resources – You can also use meta directives to stop crawling specific page or files. The only problem is – meta directives often fails when it comes to blocking multimedia files like PDFs and images.
This is where robots.txt file comes to action. You can block any specific pages on your website using robots file.
Technical robots.txt syntax
Robots files contains some syntax that you need to understand before using it. There are five common syntax that presents in robots file.
- User-agent – The specific web crawler that you are giving crawl instructions. Here is the robots database list. https://www.robotstxt.org/db.html
- Disallow – The command tells user-agent not to crawl the specific pages mentioned after disallow string. You can use only one disallow command per line.
- Allow – The command tells Googlebot to crawl a specific page or folder even its parent page or sub-folder is disallowed.
- Crawl-delay – This command tells how many seconds’ crawlers need to wait before crawling a page content. You can reset crawl delay in Search Console. https://support.google.com/webmasters/answer/48620?hl=en
- Sitemap – You need to add sitemap to robots.txt file. Because crawlers first visit this robots file and chances are high they would find all important pages present in your sitemap. However, only Google, Ask, Bing, and Yahoo supports this command.
How to find your robots txt file?
Not sure if you have a robots.txt file on your website? Simply types your root domain, add /robots.txt to end of the url.
For example – Curious Blogger’s robots.txt file can be found here – https:curiousblogger.com/robots.txt
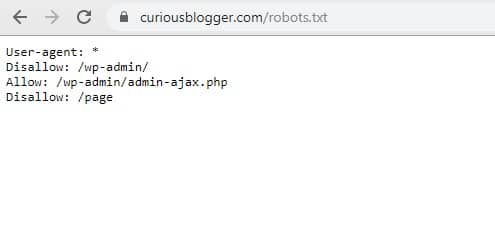
If nothing appears after putting /robots.txt file, then you don’t have a robot.txt file.
How to create robots.txt file?
Creating robots.txt file is easy. All you need a simple plain text editor and understanding of robots.txt syntax we discussed few moments ago.
Learn directly from Google to create robots.txt file.
Robots.txt Best Practices
- While creating robots.txt file make sure you are not blocking any important page
- Don’t put sensitive pages under robots.txt file. Because it can be easily seen by anyone who will access your robots file
- Blocking a page through doesn’t mean it will not appear in search engine. If the page has inbound links search engine will crawl. To block such pages you can use noindex tag
- Use wildcards to simplify instructions for web crawlers
- Use new line for each directive
- Use a separate robots.txt file for each subdomain
- Robots.txt file is case-sensitive. It means it should always be robots.txt not Robots.txt or anything else.
Where should I put my robots.txt file?
The robots.txt file always should be placed on the root of your domain. For example – if your domain it www.example.com then your robots.txt file should be placed on www.example.com/robots.txt.
Same applies for subdomain like hindi.example.com then robots.txt file should be accessible hindi.example.com/robots.txt
Robots.txt vs. Meta directives
Why using robots.txt file when you can block pages using “noindex” meta tag.
Well… using meta tags is tricky to apply on multimedia files. If you have thousands of pages adding noindex tags manually won’t be easy.
Robots.txt file best for directory wide whereas meta directives would be great choice if you want to control page level crawling.








3 thoughts on “Robots.txt – How to Make a Robots.txt File for SEO”
Thanks guys, I was struggling with this creepy robots file for so long. Now I get the idea.
Thank you Umesh and team, as this robot.txt is simple in looks but sometimes creates a mess in minds of SEOs. The description is simple and clear considering both the beginners as well as an experienced one. Nice post
Thanks for this, i initially copied and pasted a robot.txt file i saw on quora, buh now i think i should do better by following your instruction